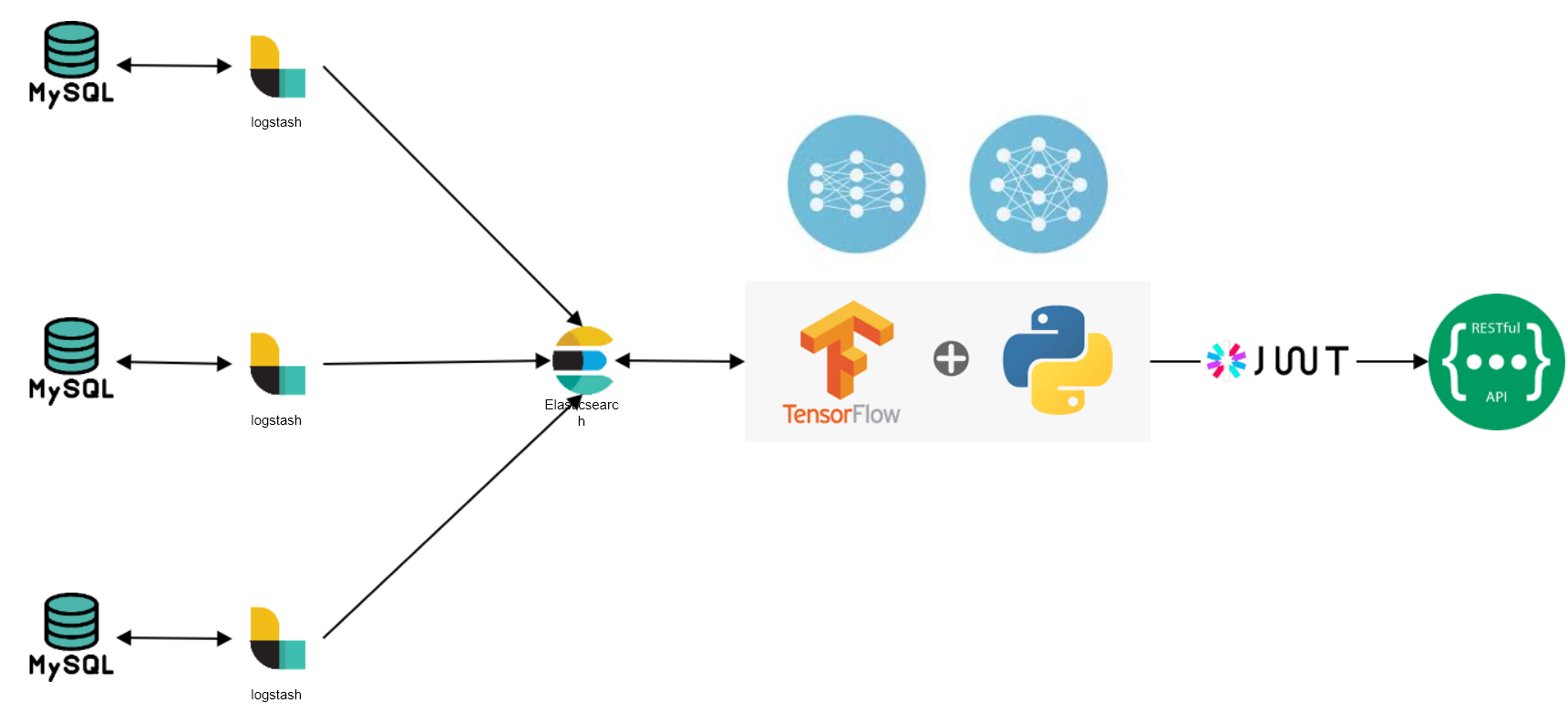
기능설명
특징
TensorFlow Recommenders
TFRS(TensorFlow Recommenders)는 추천자 시스템 모델을 빌드하기 위한 라이브러리입니다. 추천자 시스템을 빌드하는 전체 워크플로(데이터 준비, 모델 공식화, 학습, 평가 및 배포)에 도움이 됩니다. Keras에 기반하며 복잡한 모델을 빌드하는 유연성을 제공하면서 완만한 학습 곡선을 갖추는 것을 목표로 합니다.
사용 및 관리 편의성
항목, 사용자, 컨텍스트 정보를 추천 모델에 자유롭게 통합합니다.공동으로 여러 추천 객체를 최적화하는 멀티태스크 모델을 학습시킵니다.
유연한 확장성
유연한 추천 검색 모델을 빌드하고 평가합니다.
오픈 소스 도구 지원
TFRS는 오픈소스이며 GitHub에서 사용 가능합니다.
상세기능
소개
머신러닝(ML) 소개
머신러닝은 소프트웨어가 명시적인 프로그래밍이나 규칙 없이 작업을 실행하도록 돕는 방식입니다. 기존의 컴퓨터 프로그래밍에서는 프로그래머가 컴퓨터가 사용해야 할 규칙을 지정하지만, ML에서는 다른 사고방식이 필요합니다. 실제 ML은 코딩보다 데이터 분석에 훨씬 더 중점을 둡니다. 프로그래머는 일련의 예제를 제공하고 컴퓨터는 데이터로부터 패턴을 학습합니다. 머신러닝은 "데이터를 이용한 프로그래밍" 이라고 생각할 수 있습니다.
머신러닝(ML) 문제를 해결 과정
ML 사용하여 데이터에서 해답을 얻는 과정에는 여러 단계가 있습니다. 텍스트 분류의 전체 워크플로를 보여 주고 데이터 세트 수집, TensorFlow를 이용한 모델 학습 및 평가와 같은 중요한 단계를 거쳐 Hyperparameters 값을 조정하며 최종 모델 배포를 합니다.

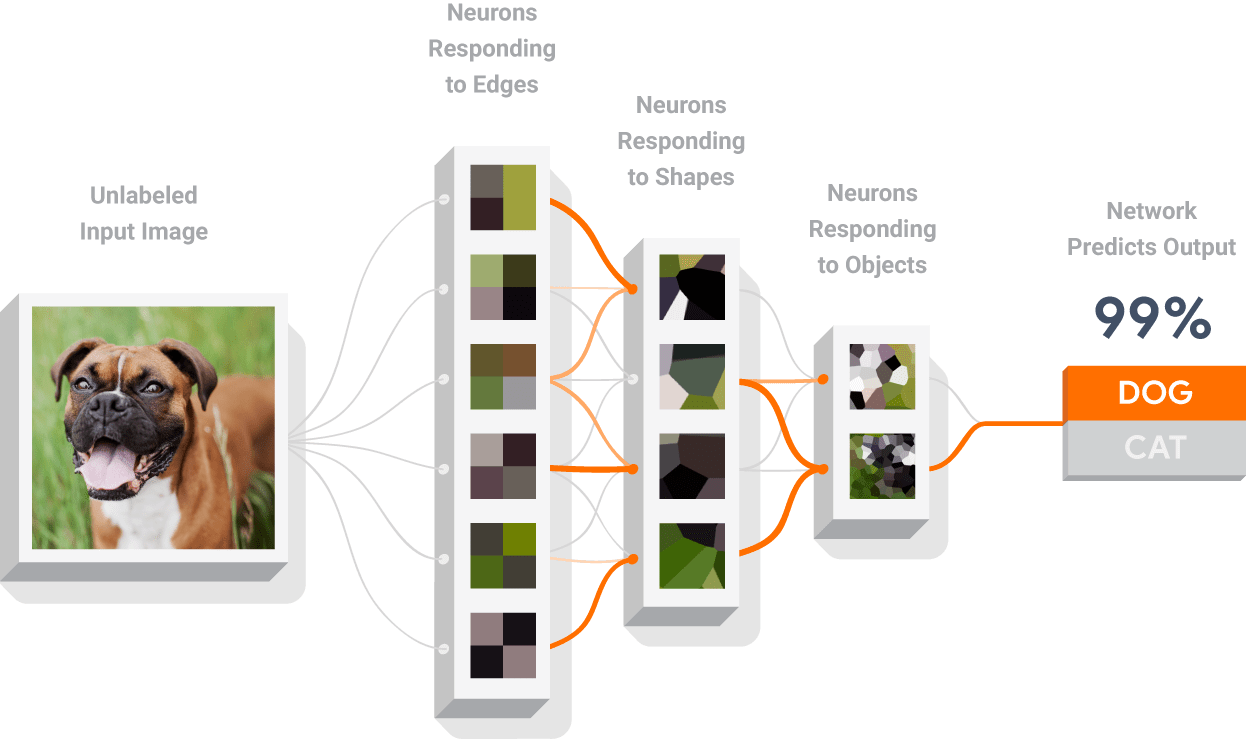
신경망 구조
신경망은 패턴을 인식하도록 학습시킬 수 있는 모델 유형으로서, 입력 및 출력 레이어, 하나 이상의 히든 레이어 를 비롯한 다양한 레이어로 구성됩니다. 각 레이어의 뉴런은 추상화 수준이 점점 높아지는 데이터 표현을 학습합니다. 예를 들어, 이 시각적 다이어그램에는 선, 모양, 텍스처를 감지하는 뉴런이 있습니다. 이러한 표현(또는 학습된 특성)을 사용하여 데이터를 분류할 수 있습니다.
신경망 학습
신경망은 경사하강법(gradient descent algorithm)을 통해 학습합니다. 각 레이어의 가중치는 임의의 값으로 시작하며, 시간이 지남에 따라 반복적으로 개선되어 신경망의 정확도를 높입니다. 손실 함수는 신경망의 부정확성을 정량화하는 데 사용되며, 손실을 줄이기 위해 각 가중치를 늘리거나 줄여야 하는지를 결정하기 위해 역전파(Backpropagation) 라는 절차가 사용됩니다

추천시스템 TFRS(TensorFlow Recommenders)
Retrieval and Ranking
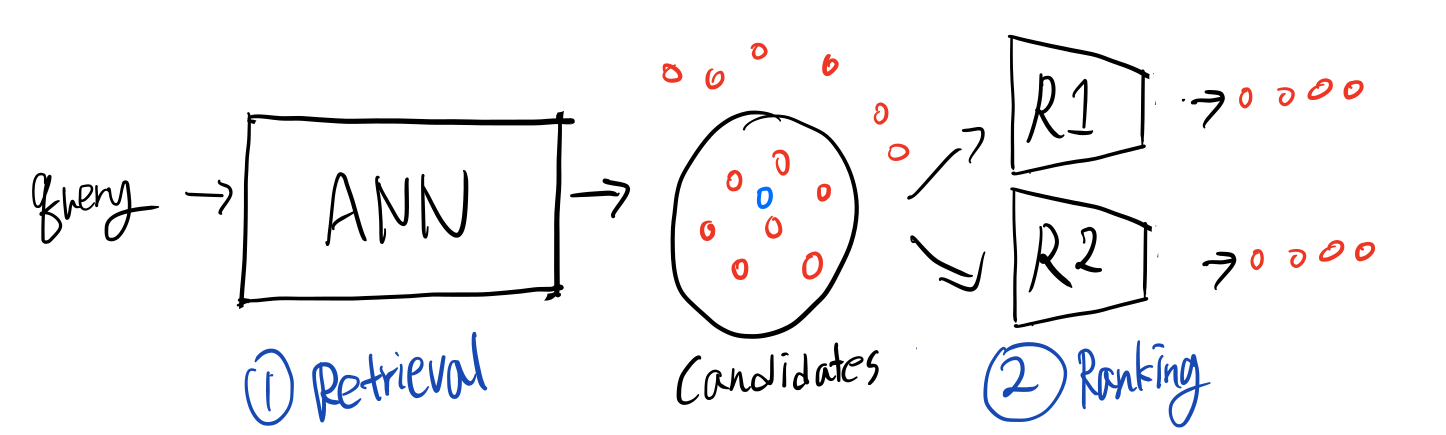
데이터베이스에 존재하는 수많은 아이템들 중 유저의 입맛에 맞는 아이템을 추천해주기까지의 과정은 Retrieval과 Ranking 두 단계로 나눠볼 수 있습니다.
첫 번째 단계는 추천 후보군을 추리는 Retrieval 과정입니다. 유저가 서비스에 접속하면 시스템은 접속 유저의 추천 목록을 구성하기 위해 아이템들을 정렬해야 합니다. 데이터베이스에 존재하는 모든 아이템에 대해 추천 점수를 계산하고, 이를 정렬해 순위를 정하는 것은 실제 서비스에서 실시간 유저 요청을 처리하기에 너무나 오랜 시간이 소요됩니다. 따라서 수백만이 넘는 아이템들 중 유저가 관심있어할만한 후보군을 우선 추려주는 작업이 필요합니다.
다음 단계는 Ranking으로, Retrieval을 통해 우선 추려둔 후보 아이템들을 대상으로 순위를 매기는 단계입니다. 이 과정에서는 추천 성능을 끌어올리기 위해 좀 더 복잡하고 정교한 모델을 사용합니다. 요새 많이 등장하는 딥러닝 모델부터 캐글에서 언제나 높은 성능을 보이는 tree 기반의 GBM등등 다양한 모델을 사용할 수 있으며, 필요에 따라 새로운 모델을 도입하기도 합니다. 실제 서비스에서는 단일 모델에 의존하기보다는 우선 다양한 모델을 서빙하고, 유저의 피드백을 반영해 선호하는 모델의 추천 가중치를 결정하는 A/B 테스팅을 진행합니다.
이렇듯 많은 추천 모델들은 복잡한 내부구조를 가지며, 새로운 모델들을 계속 실험/도입해야 합니다. 그 과정에서 모델링뿐만 아니라 데이터 파이프라인, loss function, 샘플링 로직 등등 추가적으로 요구되는 기능들 역시 함께 늘어납니다. TFRS는 Retrieval, ranking 모델을 구현할 때 필요한 다양한 보조기능들을 제공해 불필요한 코드를 줄이고 TFRS만의 base class를 활용한 일종의 boilerplate를 제공합니다. 따라서 사용자들은 모델링에 집중할 수 있게 됩니다. 이러한 특징은 많은 추천 오픈소스들이 최적화된 모델을 미리 구현해 제공하는 것과 차별되는 부분입니다.
Factorized Two-tower Model
구글에서 나오는 추천 관련 자료를 읽다보면 Factorized Two-tower 모델이라는 표현을 가끔 접할 수 있습니다. Two-tower라는 이름에서 유추할 수 있듯 User tower와 Item tower로 이루어진 두 하위 네트워크로 구성된 모델들을 의미하며, 각각의 하위 네트워크는 동일한 차원의 user/item embedding을 계산하는 데 사용됩니다. 또 Factorized Model은 두 벡터의 inner product로 user와 item의 유사도, 혹은 추천 점수를 계산하게 됩니다. 대표적으로 Matrix Factorizaton이 Two-tower 모델의 가장 단순한 버전이라 볼 수 있으며, 필요에 따라 각각의 user와 item의 다양한 feature들을 활용해 복잡한 하위 네트워크을 구성할 수도 있습니다.
여기서 핵심은 최종 유사도는 두 임베딩의 inner product(dot product)로 계산해야 한다는 점입니다. 최근에는 inner product 대신 두 임베딩을 이어붙인 뒤 layer를 쌓아올려 추천 점수를 계산하는 MLP 기반 유사도 모델 역시 꾸준히 제안되어 왔지만(NCF), 구글은 여러 논문(RecSys’20, WSDM’18, arXiv)에서 MLP로는 inner product를 근사하기 어려우며, 추천 성능 역시 떨어진다는 점을 지적합니다.
Factorized Two-tower 모델의 또다른 장점은 Retrieval 모델을 구현할 때 효과적으로 활용될 수 있다는 점인데요, 이는 아래 단락애서 살펴보도록 하겠습니다.

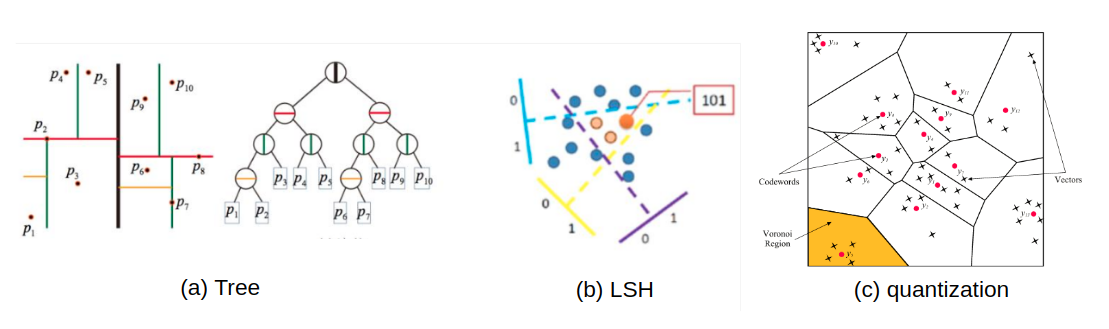
Approximate Nearest NeighborPermalink
앞서 Retrieval/Ranking 단락에서 언급하였듯 모든 아이템의 추천 점수를 구하고 이를 정렬하는 것은 무척 오랜 시간이 걸립니다. 하지만 유저 벡터와 아이템 벡터가 같은 공간에 표현된다면, 근사 최근접이웃 탐색((Approximate Nearest Neighbour, ANN)을 활용해 유저 벡터와 이웃한 아이템 벡터들을 빠르고 효율적으로 찾을 수 있습니다.
근사 최근접이웃 탐색은 벡터공간에서 주어진 벡터와 이웃한 벡터를 ‘대략적’으로 빠르게 탐색하는 알고리즘입니다. 여기서 ‘대략적’이라는 의미는 정확도를 일부 포기하는 대신(이웃한 벡터를 일부 놓치는 대신) 탐색에 소요되는 시간을 줄인다는 뜻입니다. 그 중에서 Maximim Inner Product Search (MIPS) 는 두 벡터의 유사도, 혹은 distance metric이 inner product로 정의되었을 때의 근사 최근접이웃 탐색 방법들을 의미합니다. Factorized 모델처럼 추천 점수가 dot product에 비례한다면 MIPS를 활용해 후보 아이템들을 추릴 수 있습니다. 추천시스템은 이를 활용해 유저와 가까운 아이템들을 빠르게 추려낸 뒤 Ranking 모델을 활용해 이들의 순위를 정교하게 결정합니다.
API 제공
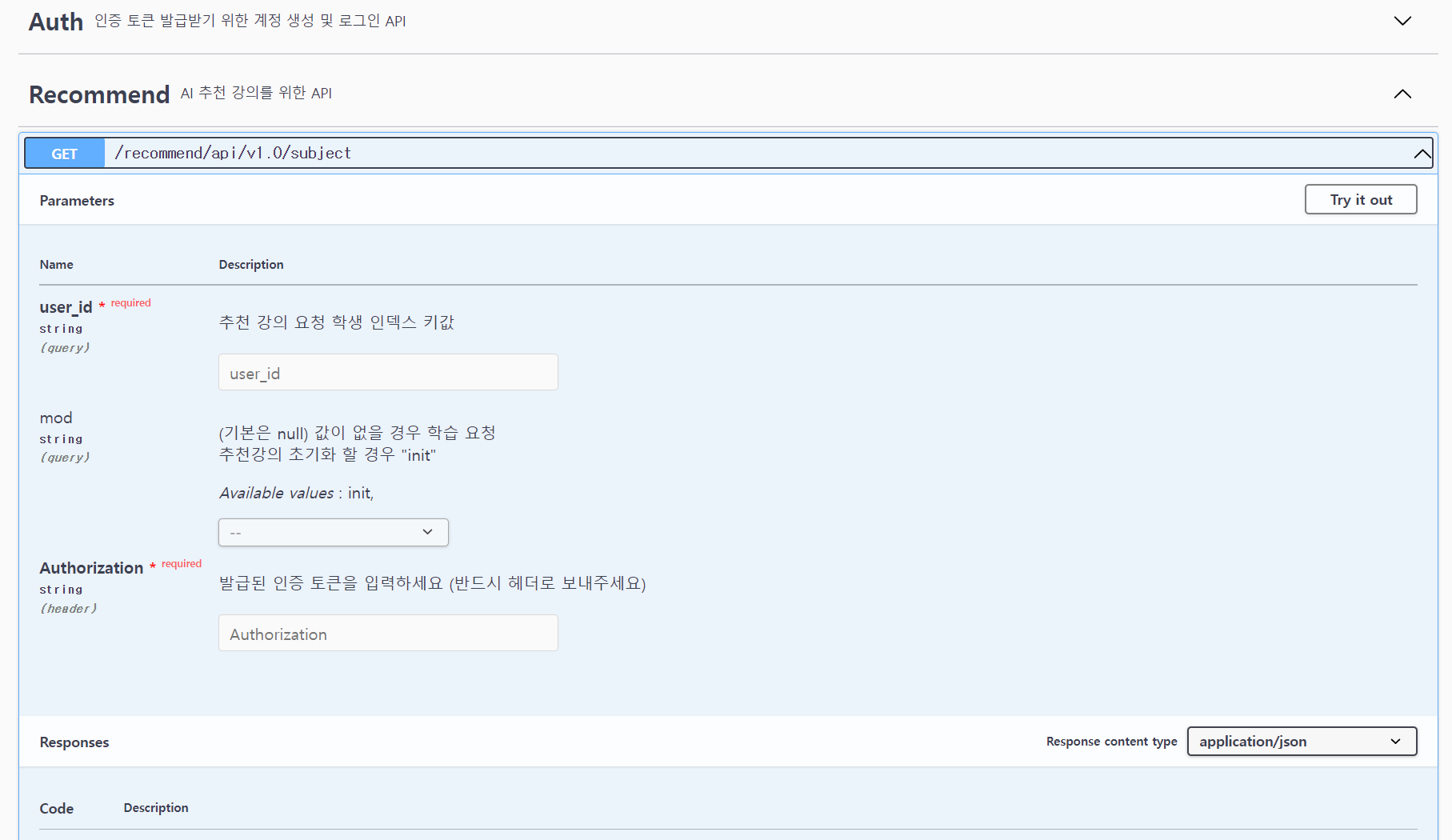
API 이용
비로그인 오픈 API이므로, POST로 호출할 때 HTTP Header에 애플리케이션 등록 시 발급받은 Token 값을 같이 전송해 주시면 서비스 이용이 가능합니다.
대학 추천 강의 API
TFRS 를 이용 하여 대학 추천 강의 API 제공