기능설명
특징
한국어에 최적화된 분석 기술 서비스
mecab-ko-dic 사전에 나오는 어떤 단어든지 효율적으로 검색할 수 있는 구조의 바이너리 사전을 갖추었으니, 한국어로 작성된 어떤 입력이든 가장 그럴듯하게 분할(viterbi path)하도록, 텍스트를 Viterbi 알고리즘으로 분석할 수 있습니다. 아래 그림은 21세기 세종계획이라는 문장을 가지고 만든 viterbi lattice입니다.
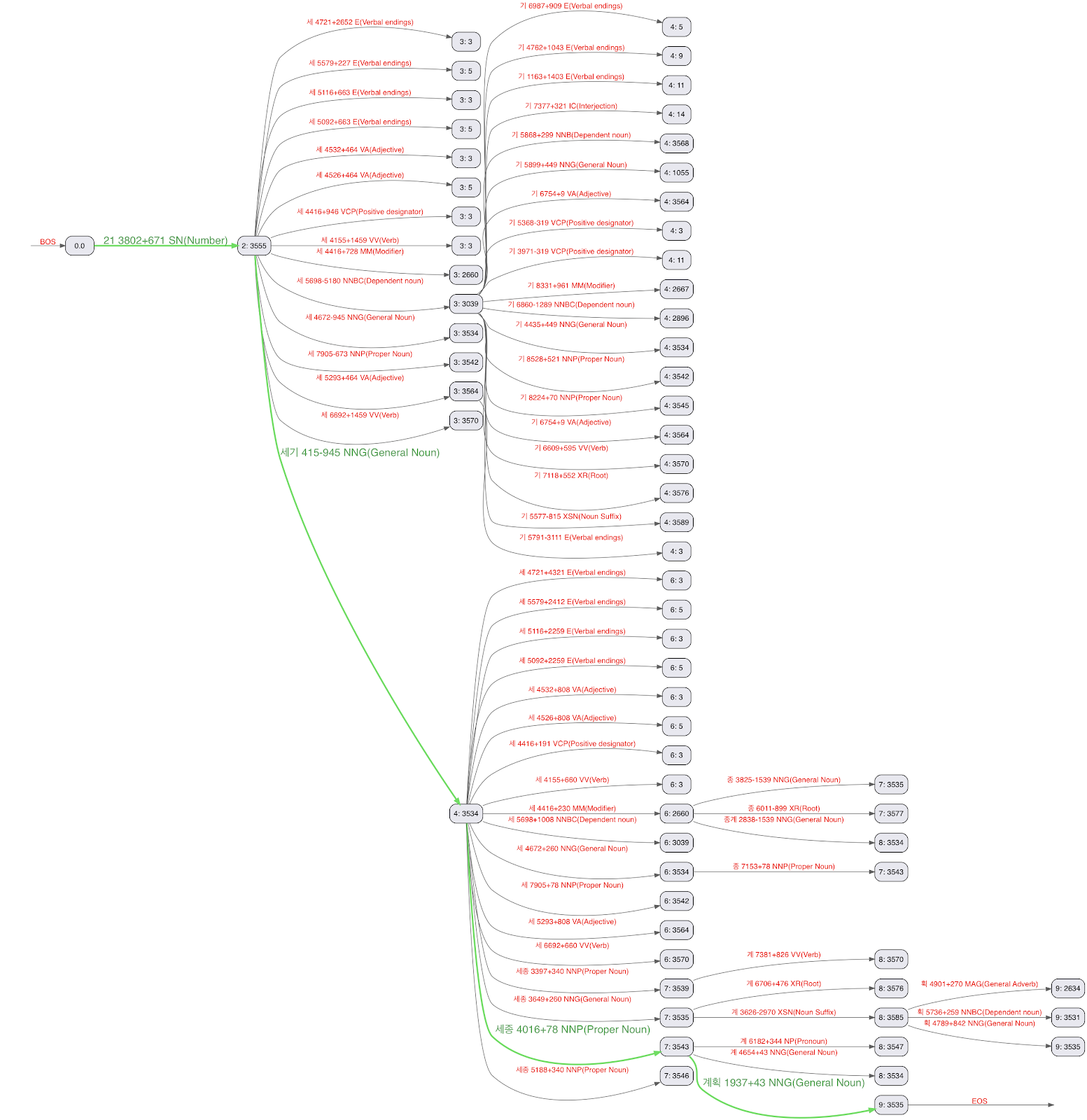
viterbi path 중 초록색이 노리가 출력하는 분할 결과입니다.
21 + 세기 (century) + 세종 (Sejong) + 계획 (Plan)
가장 좋은 분할을 찾는 알고리즘은 보통 세 단계 과정을 거칩니다. 먼저 입력에서 다음 문장 경계를 찾습니다. 그 다음 이 문장의 모든 가능한 경로의 격자를 만들고 마지막으로 각 전이의 비용을 적용함으로써 최적의 경로(분할)를 계산합니다. 입력된 모든 문장이 처리될 때까지 이 단계들을 적용합니다. 단계들을 순차적으로 적용하면 느려질 수 있으므로, 노리는 다른 접근 방법, 즉 처리량에 최적화된 단일 단계를 사용합니다. 노리는 입력을 글자 단위로 처리하며 viterbi lattice를 바로바로 만듭니다. 비용도 각 글자 경계에서 가장 비용이 낮은 경로를 유지하기 위해 바로바로 계산됩니다. 예를 들어, 위 그림에서 경로 21 + 세 + 세는 21 + 세기의 비용이 더 낮음을 발견하자마자 제거됩니다. 각 경계의 끝(특정 상태에서 가능한 전이가 하나뿐일 때)이나 1024 글자를 현재 격자의 최적 분할을 출력한 다음 처리를 마치고 다음 문자 윈도우(character window)에서 재개합니다.
상세기능
지원 기능
제공 서비스
입력된 텍스트를 RESTful API 방식으로 전달하면 서버에서 인식해 mp3 포맷의 스트리밍 데이터나 파일로 리턴해주는 API입니다.
API 제공
API 이용
비로그인 오픈 API이므로, POST로 호출할 때 HTTP Header에 애플리케이션 등록 시 발급받은 Token 값을 같이 전송해 주시면 서비스 이용이 가능합니다.
Development API 제공
프로젝트를 생성하고 인증서 등록을 완료하면, 실제 서비스 코드에 적용할 수 있는 Development API 가이드가 제공됩니다. 이를 통해 실제 전송 테스트까지 진행할 수 있습니다. API 기능은 지속적인 업데이트를 통해 추가될 예정입니다.