기능설명
특징
길이가 긴 문장 발화에 대한 높은 인식률
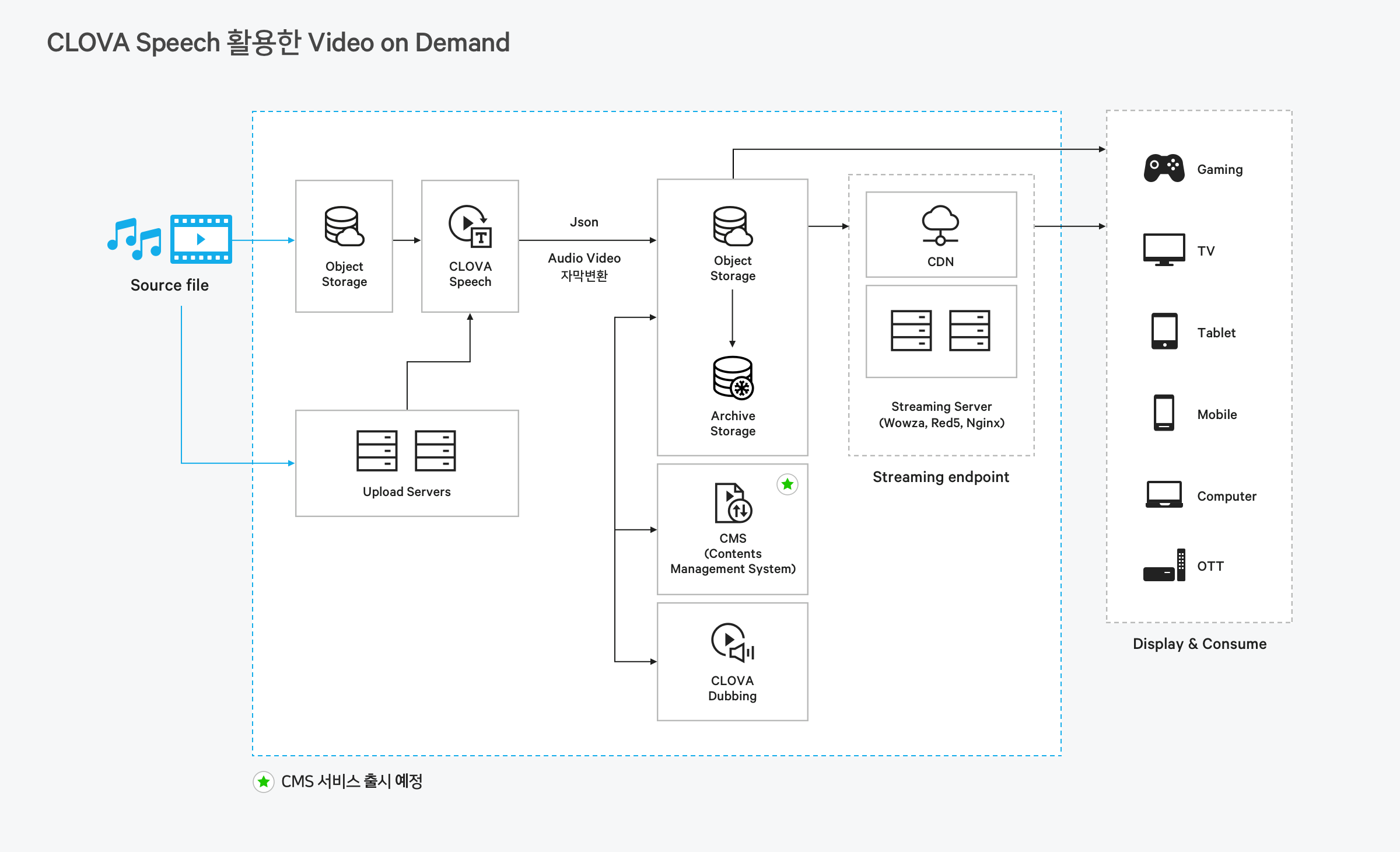
음성 메모, 영상 자막 생성, 통화 녹취록 관리 등 음성 기반 서비스를 만들 때 활용할 수 있습니다.
장문 발화 인식에 특화된 엔진
Speech 엔진은 AI 기술을 이용하여 길고 복잡한 문장을 읽는 음성을 정확하게 인식합니다. 특히 한국어 장문 발화에 최적화된 자동 딕테이션 기능으로 방송 영상이나 오디오 클립과 같이 길이가 긴 미디어 음성을 간편하게 텍스트로 변환할 수 있습니다.
활용 가능 영역
동영상자막
학습동영상 적용되어 자동 자막 생성 기능을 제공하고 있습니다.
고객센터
고객센터의 음성 데이터를 텍스트화하여 손쉽게 관리하실 수 있습니다.
오디오/비디오 관리
오디오와 비디오 데이터의 음성을 텍스트화하여 아카이빙하고 분석하실 수 있습니다.
자동 자막 생성
타임 스탬프 기능을 통해 손쉽게 자막을 생성할 수 있습니다.
상세기능
지원 기능
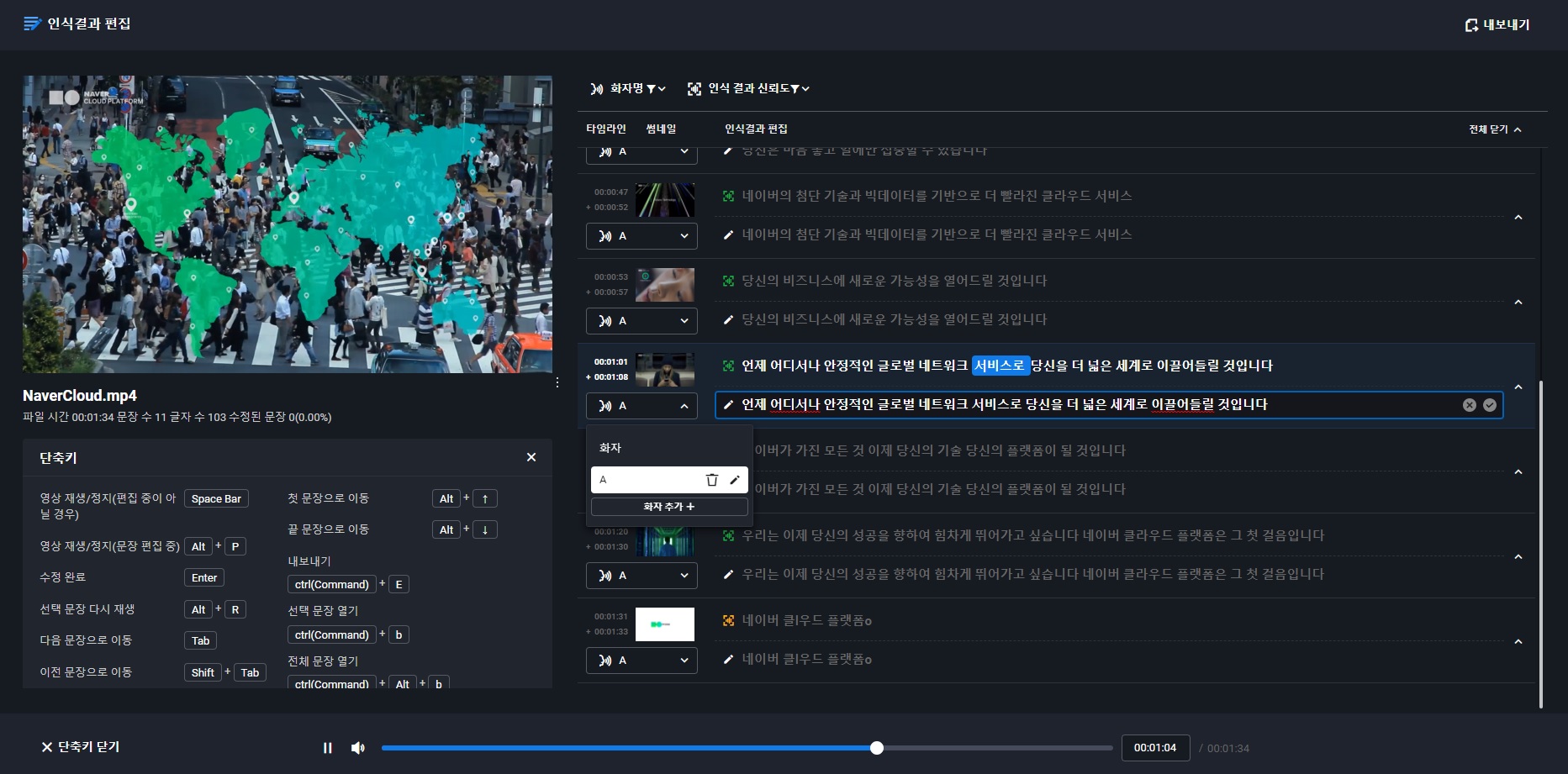
문장 자동 분리 및 타임스탬프 지원
타임스탬프 기능을 제공하여 음성을 텍스트로 변환하는 과정에서 적절한 길이로 문장을 분리하고 시간을 표시합니다. 또한 문장의 시작과 끝을 시각적으로 표시해 주어 자막을 생성하는 등 다양한 방식으로 활용할 수 있습니다.
키워드 부스팅
키워드 부스팅 기능을 사용하여 인식 확률을 높이고 싶은 단어를 미리 설정할 수 있습니다. 등록할 수 있는 문자 및 언어는 한글, 영어, 일본어, 숫자입니다.
인식 결과 수정 에디터 제공
Speech를 통해 인식된 데이터를 손쉽게 수정, 편집하여 재가공할 수 있습니다. 편집하려는 파일이 재생되고 있는 과정에서 인식된 데이터를 바로바로 수정할 수 있습니다. 인식 결과는 자막은 물론 다양한 파일 형식으로 추출할 수 있습니다.
API 제공
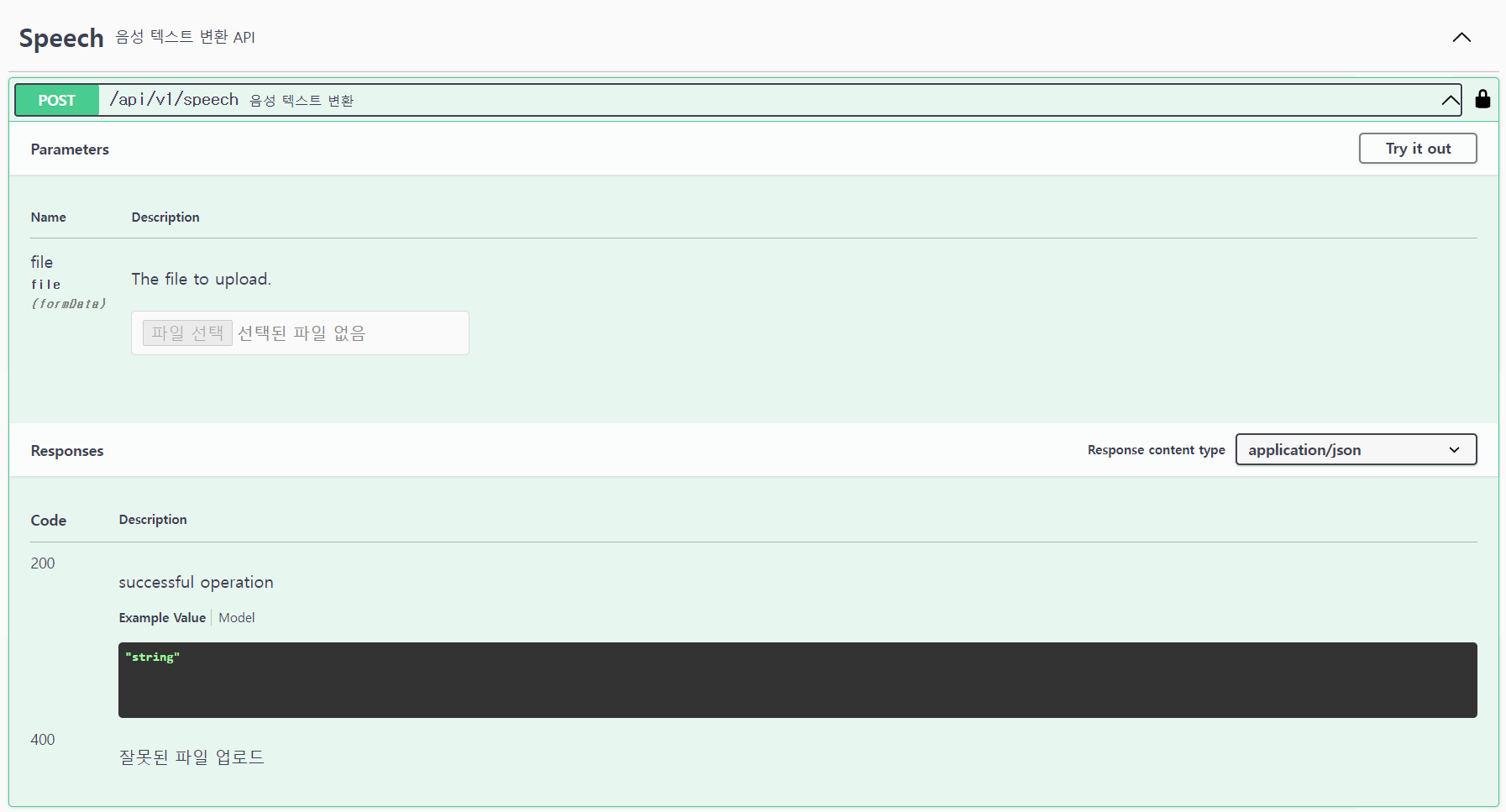
API 기반 인식 제공
Speech API를 이용하여 파일을 전송하면 서버에서 인식 결과를 텍스트로 리턴합니다. REST API는 Client ID와 Client Secret을 이용하여 인증합니다. 인증부터 API 이용까지 데이터 전송 구간은 모두 암호화를 적용할 수 있습니다.
| 이용 방식 | 인식 가능 언어 | 인식 가능 시간 | 인식 파일 크기 | 인식 가능 음성 파일 형식 | 전달 데이터 |
|---|---|---|---|---|---|
| REST API | 한국어, 영어 | 최대 2시간 | 최대 2기가 | audio: mp3, aac, ac3, ogg, flac, wav video: avi, mp4, mov, wmv, flv, mkv, m4a | 녹음파일 |